I am implementing Navier Stokes equations with moving boundary using ALE method. I want to parallelize it. Firstly, I directly movemesh in parallel without ‘move the global mesh in a single processor‘, and the result seems normal.
However, when I you try to centralize mesh velocity function, move global mesh in a single process, and re-decompose, something strange happened. The rigid cylinder deforms
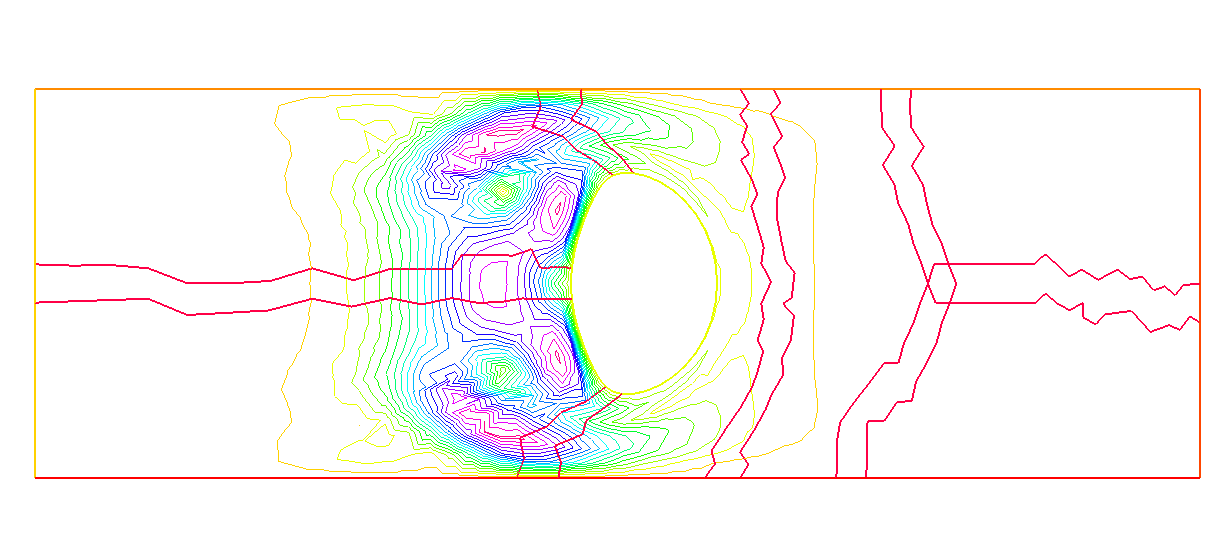
I want to do some numerical experiments to show the error when I directly use ‘movemesh‘ in parallel, and from the results, I find in this case, ‘movemesh‘ works well using 50 processors(maybe just a coincidence). The codes are
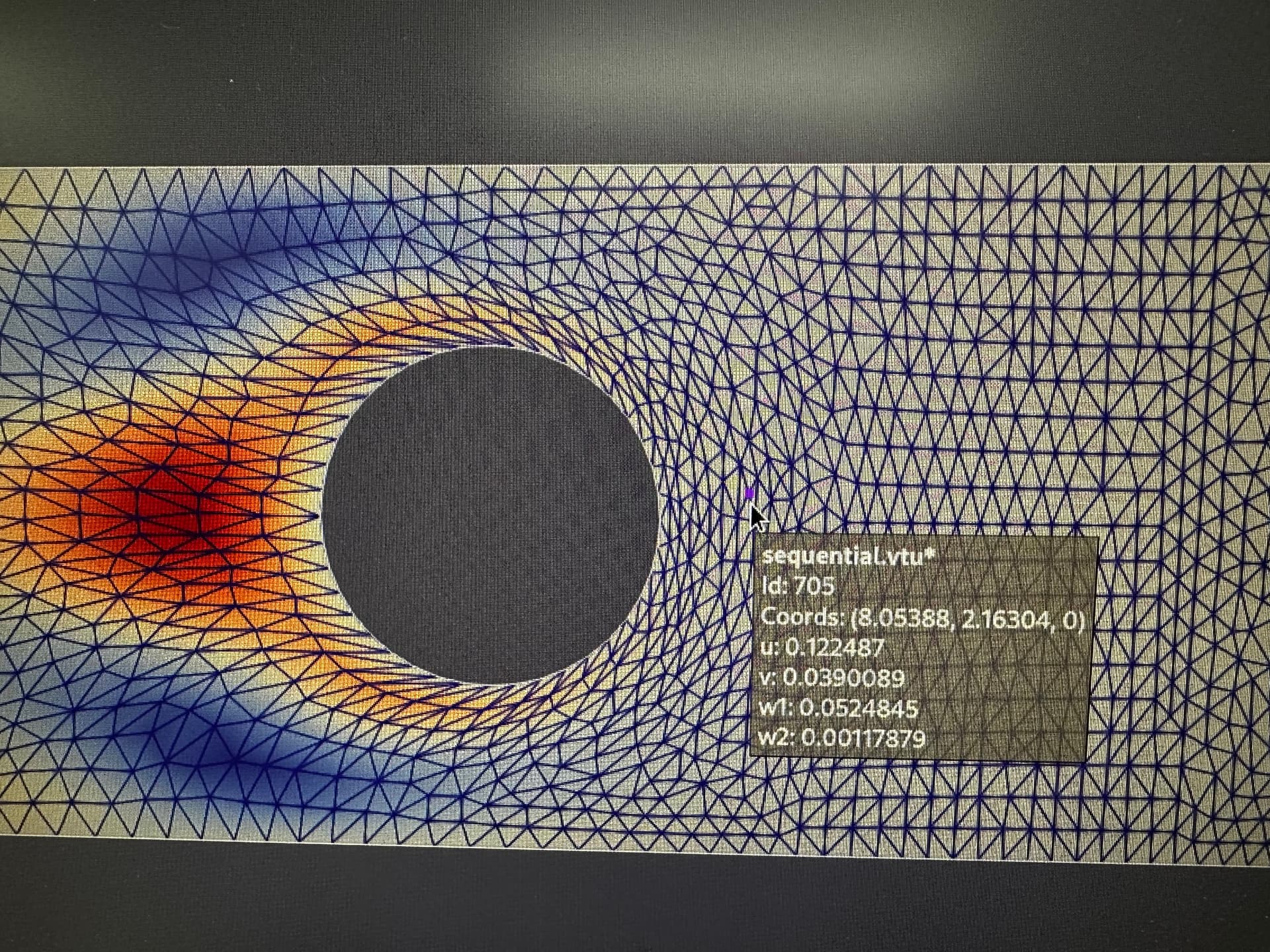
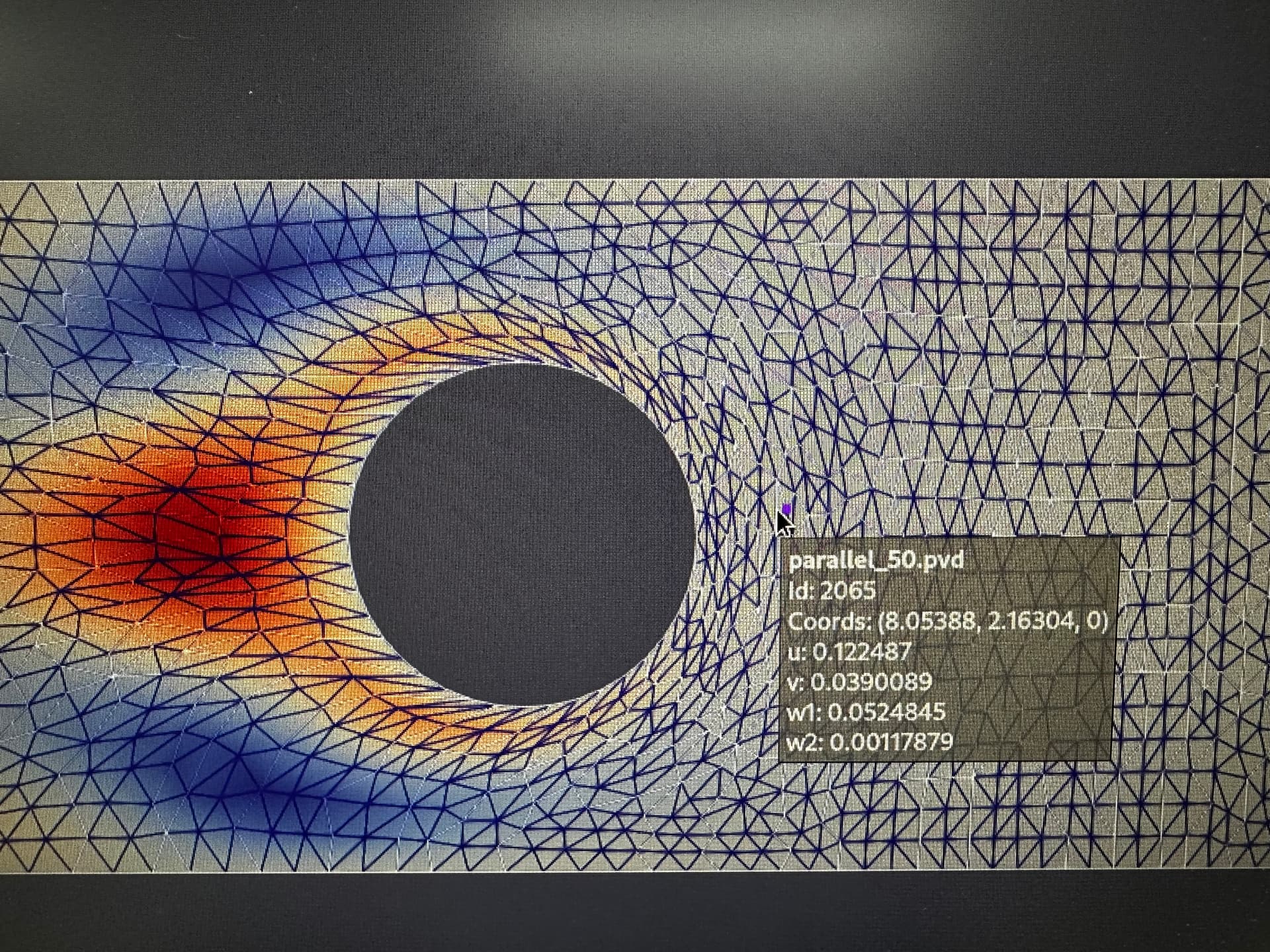
respectively (in order to magnify the error, under the assumption that more subdomains, more error, I choose 50 processors as comparison). From these three plots, they share the same maximum and minimum values. Since it’s just qualitative comparison. I try to do some quantitative comparisons in Paraview with .vtu files generated using ‘savevtk’ command.
for the sake of simplicity, here I only show one node of the last vtu/pvd file.
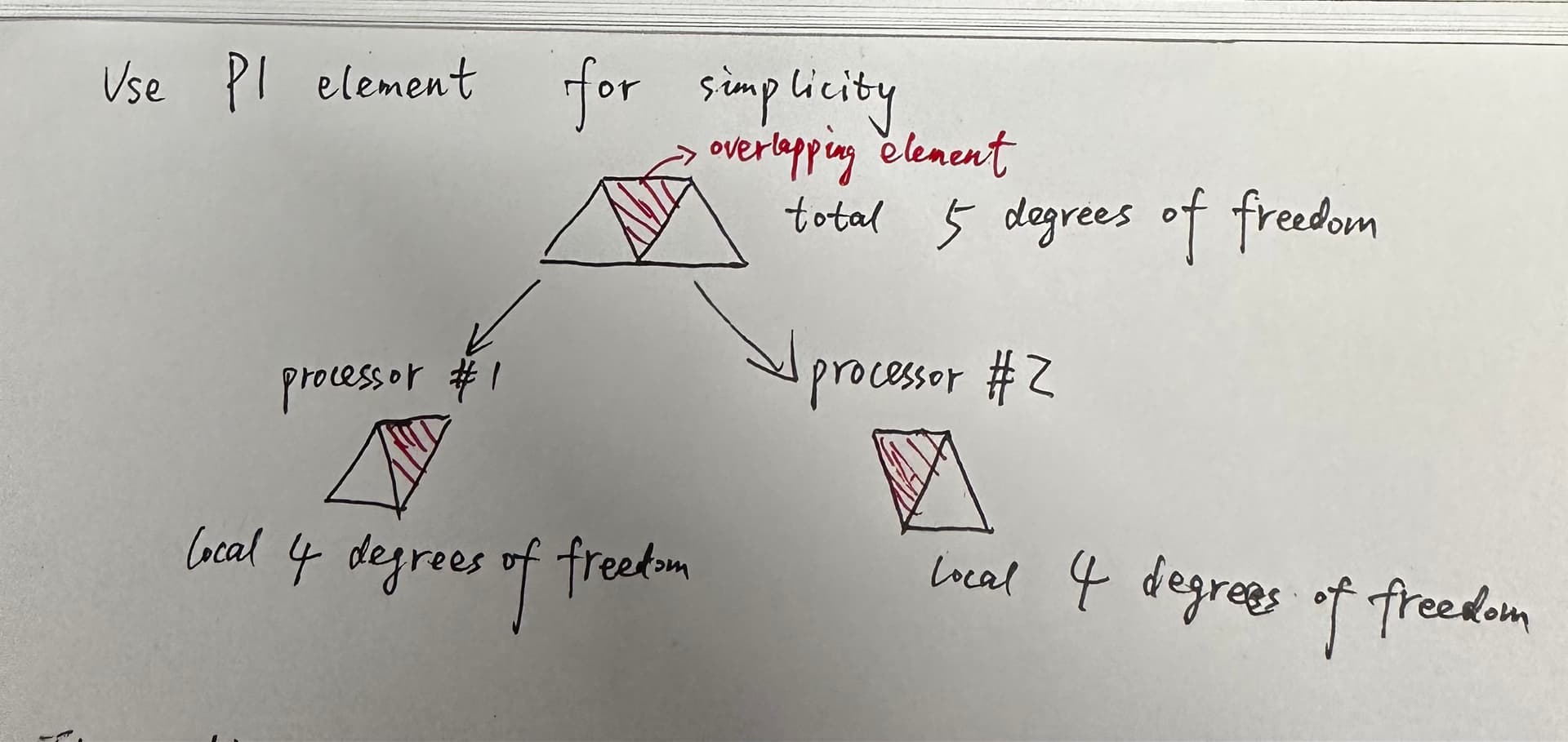
Since the ghost element actually belongs to one processor(here I assume it belongs to processor # 1), the distributed matrix A is a 5*5 matrix, after solving the linear system. The values of ghost element in processor # 2 are unknown. Are they given randomly?
Of course they are not given randomly. Ghost values are consistent among processes after operations such as matrix-vector product and solution of linear systems.