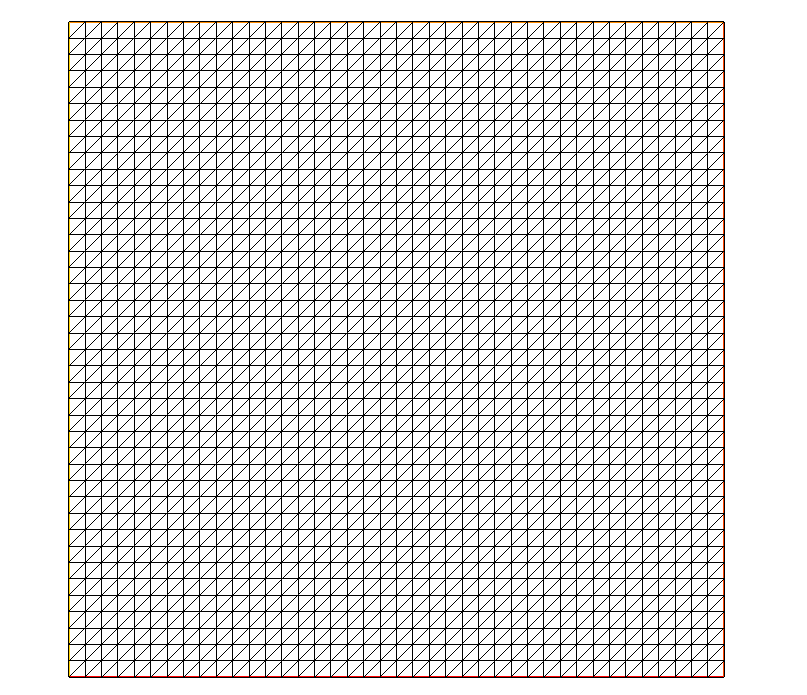
Many thanks. I have tried the command DmeshReconstruct(), I find it can generate a distributed overlapping mesh from some dispatched non-overlapping meshes.
after DmeshCreate(Th); it becomes an overlapping distribted mesh, and every piece belongs to one processor, at this time, every processor has its own local different Th,
my question is that if it is possible directly recover the global mesh like Picture 1 from dispatched meshes like Picture 2 so that every processor has the same global Th again.
Sorry to bother you again, professor, I have another irrelevant question,
I want to calculate the running time of my parallel program. At the beginning, I use mpiWtime(), but I find it returns different values from different processors. like the following picture shows
By the way, do you think the average time (here is the Time row and Avg column) is a good factor to compare the parallel efficiency? And are there other good factors to measure the parallel efficiency?
You’ll find help in the PETSc manual. Below the numbers you are reporting, there is a column “Ratio” which highlights the load imbalance between processes.